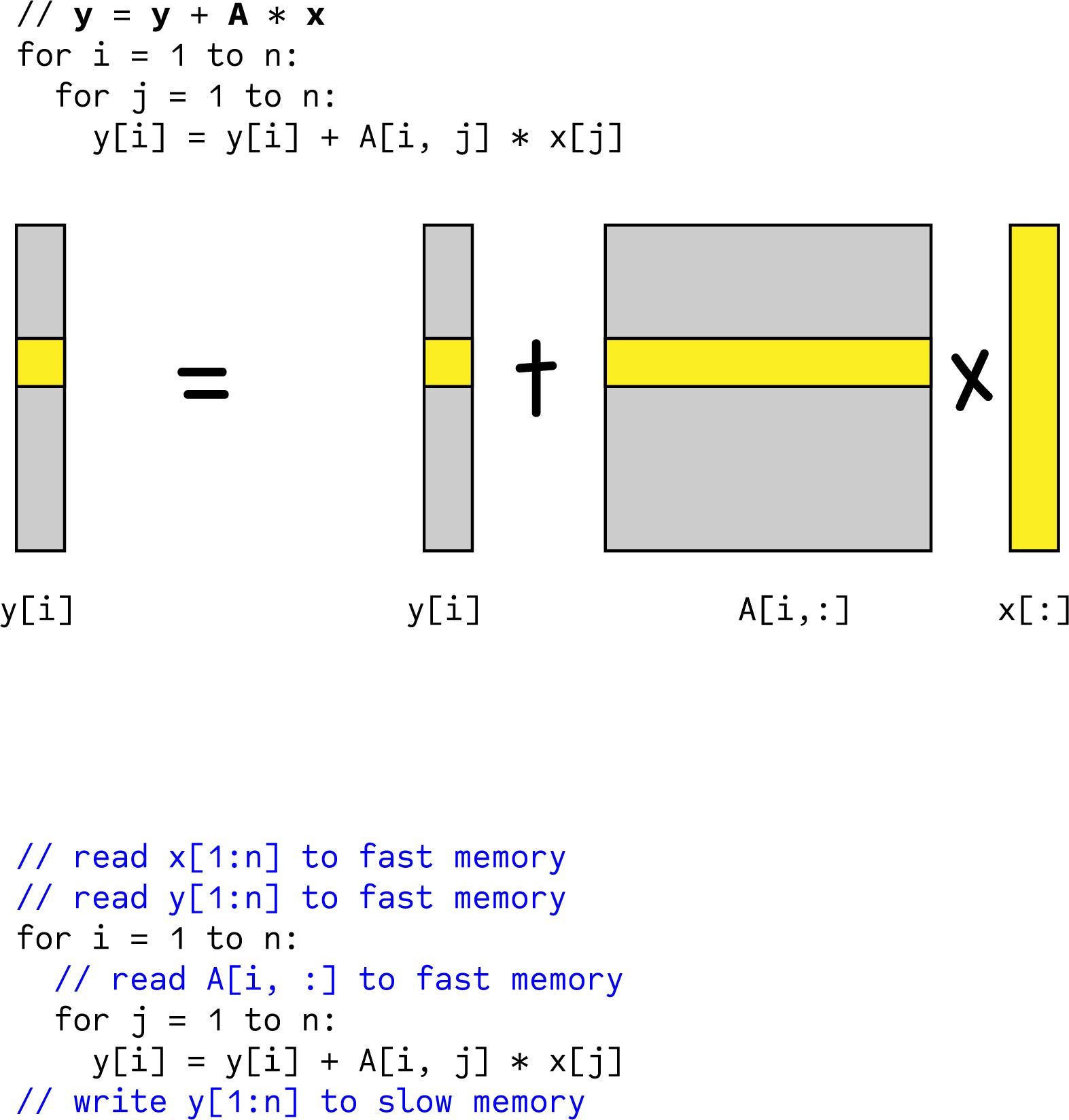
Optimize Matrix Vector Multiplication
In the GTX 280 SYMV provided by NVIDIAs CUBLAS 23 achieves up to 3 GFlopss and 5 GFlopss in single and double precision respectively. Is there a way though to further optimize less execution time matrix vector multiplication with openMP without optimizations flags when compiling the code.

This Guide Explains Linear Programming In Simple English Get Hands On Knowledge In Different Methods Of Linear Progra Linear Programming Linear Data Scientist
The underlying machine architecture.

Optimize matrix vector multiplication. Include include include include define SIZE 1000 int main float A SIZE SIZE b SIZE c SIZE. VLDB Endow 44231--242 2011. Algorithmically the SpMV kernel is as follows ij.
In this article we present a novel non-parametric self-tunable approach to data representation for computing this kernel particularly targeting sparse matrices. Our goal by targeting low-level easy to understand fundamental kernels is to develop optimization strategies that can be. Generic matrix-vector multiplication kernel is very straight-forward on GPUs because of the data parallel nature of the computation.
Programming Homework 1 - Optimize Matrix Multiplication 1262018. Init for i0. This architec-ture is described in detail in our proposal dated August 13 1982.
Vector and matrix arithmetic eg. __kernel void gemv const __global float4 M const __global float4 V uint width uint height __global float W __local float partialDotProduct Each work-group handles as many matrix. Matrix-vector multiplication routines gemvsymv which are some of the most heavily used linear algebra kernels in many important engineering and physics applications.
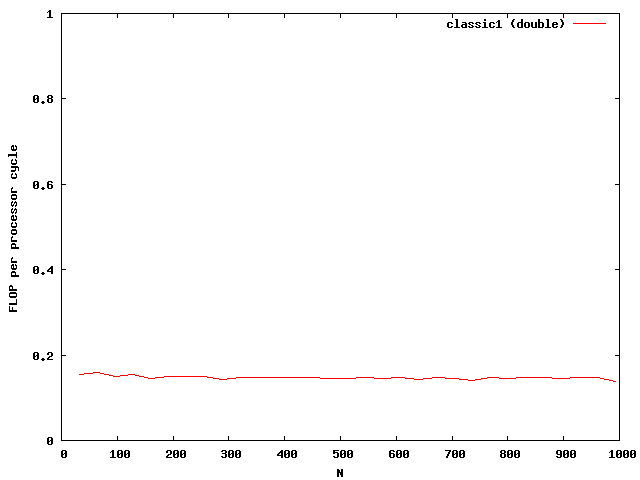
The classic implementation of the matrix vector multiplication is classic1 template class T uint64_t classic1 int size int num T A x y. Deploy iterative matrix-vector multiplication kernels on failure-prone cloud platforms. Optimization of sparse matrix-vector multiplication on emerging multicore platforms.
This need for optimization and tuning at run-time is a major distinction from the dense case. We start with an extensive study of possible memory hierarchy optimizations in particular reorganization of the matrix and computation around blocks of the matrix. Vector dot and matrix multiplication are the basic to linear algebra and are also widely used in other fields such as deep learning.
For int k 0. K num. Optical numerical analog processor for matrix-vector multiplication utilizing a computational architecture known as an engagement processor.
Evaluate the effects of replication on throughput. Partitioned Global Address Space Programming with Unified Parallel C UPC and UPC by Kathy Yelick 282018. The first is done by using the data thats currently in cache to its fullest extent for everything it needs to be used for before replacing it by other data the latter is done by prefetching data into the cache before actually making use of it.
J y i A i j x j. I for j0. Parallel Computing 353178--194 2009.
I size. Init A x y size. I am trying to optimize a Matrix-vector multiplication kernel for an Intel CPU-GPU system.
Uint64_t time1 rdtsc. Matrix multiplication has been a tricky kernel to optimize for cache prefetching because it exhibits temporal locality in addition to the normal spatial locality. Where Ge 2 4 h detJ 1 1 1 1 2 1 i e h detJ 1.
Limitations on the size of the cache and the latency to load data from memory. Uint64_t time2 rdtsc. But since the code using the controversal keyword register and I use pointer arithmetic.
Heath Optimization of Matrix-Vector Multiplication below we assume that the map from the reference element is a ne. For int j 0. Irregular data access patterns in SYMV bring challenges in optimization however.
Heres the code for the kernel. It is easy to implement vectormatrix arithmetic but when performance is needed we often resort to a highly optimized BLAS implementation such as ATLAS and OpenBLAS. Implications for graph mining.
Scaling up the sparse matrix-vector multiplication kernel on modern Graphics Processing Units GPU has been at the heart of numerous studies in both academia and industry. ICloud Computing and Big Data Processing by Shivaram Venkataraman 2132018. Libraries that optimize matrix-vector products do so by working around two issues.
Optimizing matrix vector multiplication with keyword register and unsafe pointer arithmetic. We consider the SpMV operation y y Ax where A is a sparse matrix and xy are dense vectors. I know this piece of code is quite strange but it does its job very well performance-wise reducing the running time of a very computation intensive operation by 3 - 5 times without using a better algorithm.
Return time2 - time1. J size. We refer to x as the source vector and y as the destination vector.
Distributed Memory Machines and Programming 262018. Fast sparse matrix-vector multiplication on gpus. It is one of the level 2 sparse basic linear algebra subprograms BLAS and is one of the most frequently called kernels in.
I y i 0. Briefly described it is a variation of the systolic architecture proposed by Kung 1 for use in VLSI electronics. I know that gemvBLAS-2 is memory bound but I want to obtain the best performance possible.
Recent Intel processors families use many prefetching systems to augment the codes speed and aid performance. K for int i 0. Finish A x y.
The sparse matrix-vector multiplication SpMV operation multiples a sparse matrix A with a dense vector x and gives a resulting dense vector y. In this tensor formulation of the 2D Laplace equation for example the local sti ness matrix Seis given by Se ij X2 m1 X2 n1 Ge mn K ijmn K. Aspect Percent Homework 25 Lab assignments 25 Midterm Exam 25 Final Exam 25 Title Author Fundamentals of Database Systems Ramez Elmasri and Shamkant Navathe.
This thesis presents a toolkit called Sparsity for the automatic optimization of sparse matrix-vector multiplication. Google Scholar Digital Library.

Pin On Redes Neuronales

Evolving Design Genetic Algorithm Generative Design Genetic Information

Pin On From Website

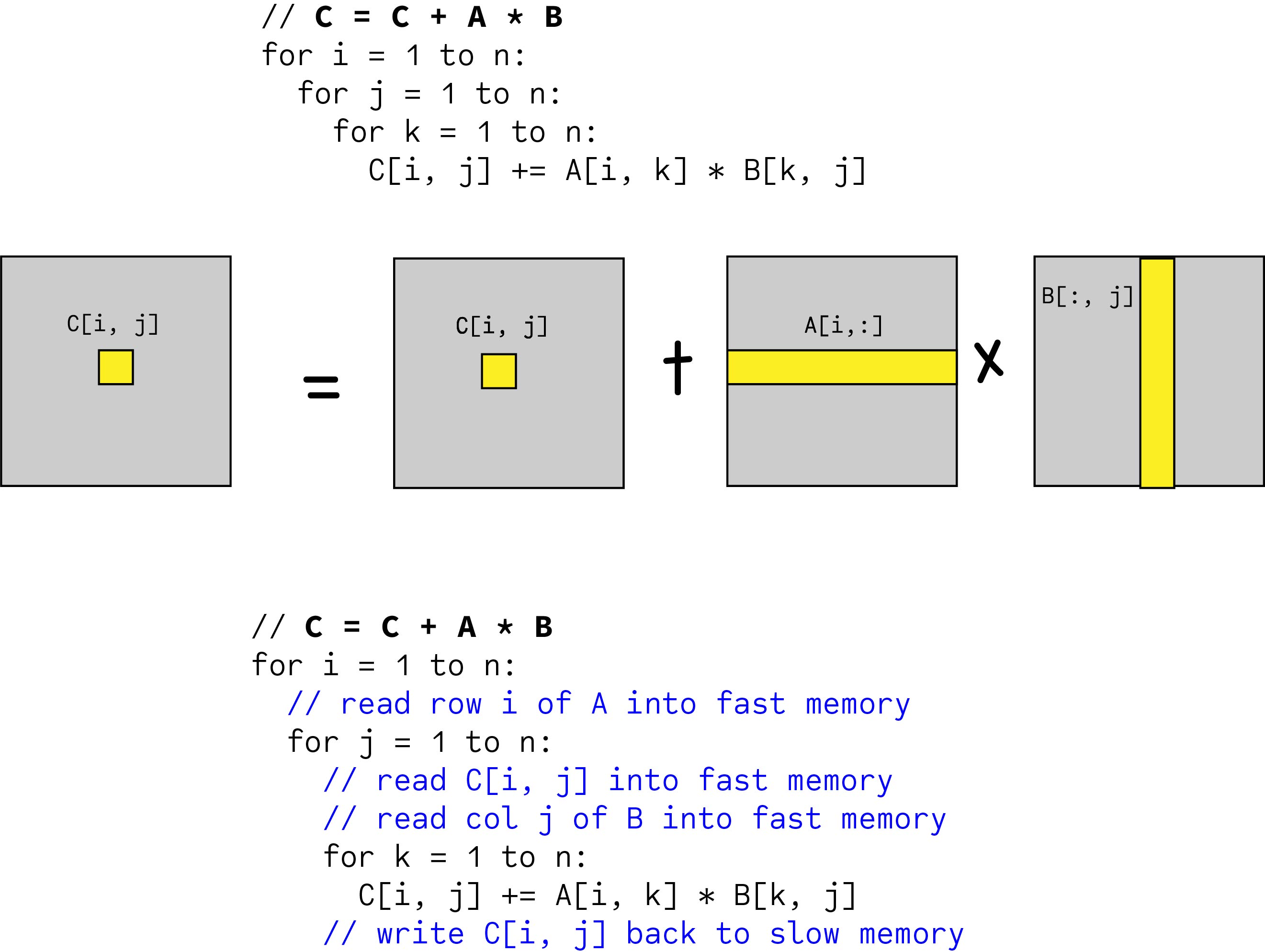
Toward An Optimal Matrix Multiplication Algorithm Kilichbek Haydarov
Blocked Matrix Multiplication Malith Jayaweera
Blocked Matrix Multiplication Malith Jayaweera
Fast Matrix Vector Multiplication
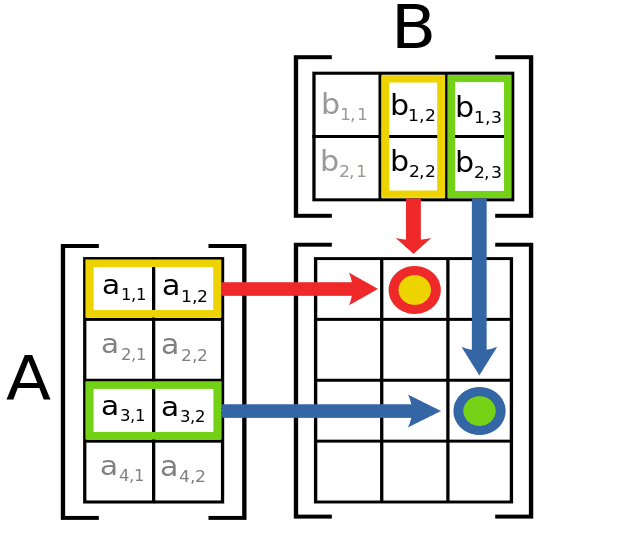
Introduction To Matrices And Matrix Arithmetic For Machine Learning

Pin On Useful Links
Blocked Matrix Multiplication Malith Jayaweera

Toward An Optimal Matrix Multiplication Algorithm Kilichbek Haydarov

Pin On Math Aids Com

Pin On Math

Parallel Matrix Multiplication C Parallel Processing By Roshan Alwis Tech Vision Medium
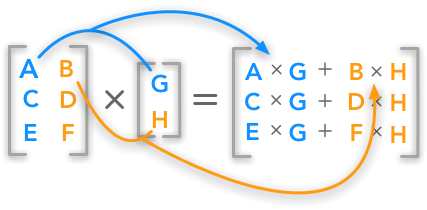
Introduction To Matrices And Vectors Multiplication Using Python Numpy

C Mpi Partition Matrix Into Blocks Stack Overflow This Or That Questions Matrix Partition

I Ll Figure It Out A Guide To Actually Figuring Life Out School Apps Learning Math Basic Math
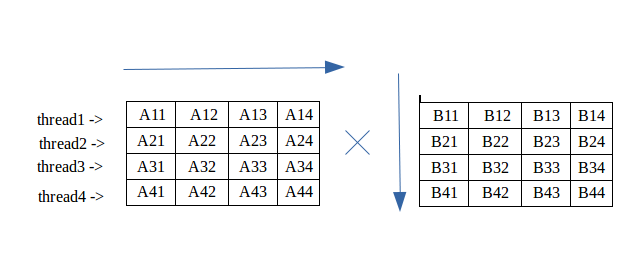
Multiplication Of Matrix Using Threads Geeksforgeeks

Pin On Data Science Resources