Cuda Matrix Multiplication Shared Memory Example
Err cudaMemcpyd_Aelements Aelements size cudaMemcpyHostToDevice. April 2017 Slide 6 Define dimensions of grid On Jureca Tesla K80.

Matrix Multiplication Cuda Eca Gpu 2018 2019
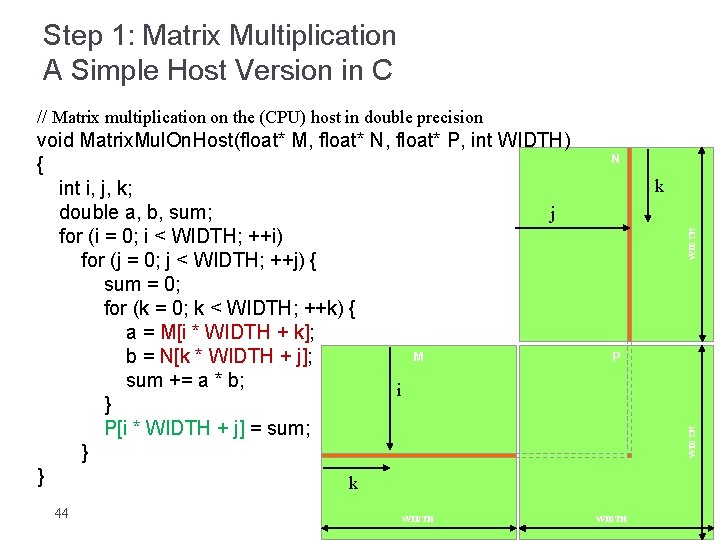
Examples of Cuda code 1 The dot product 2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop void saxpy_serialint n float alpha float x float y forint i 0.
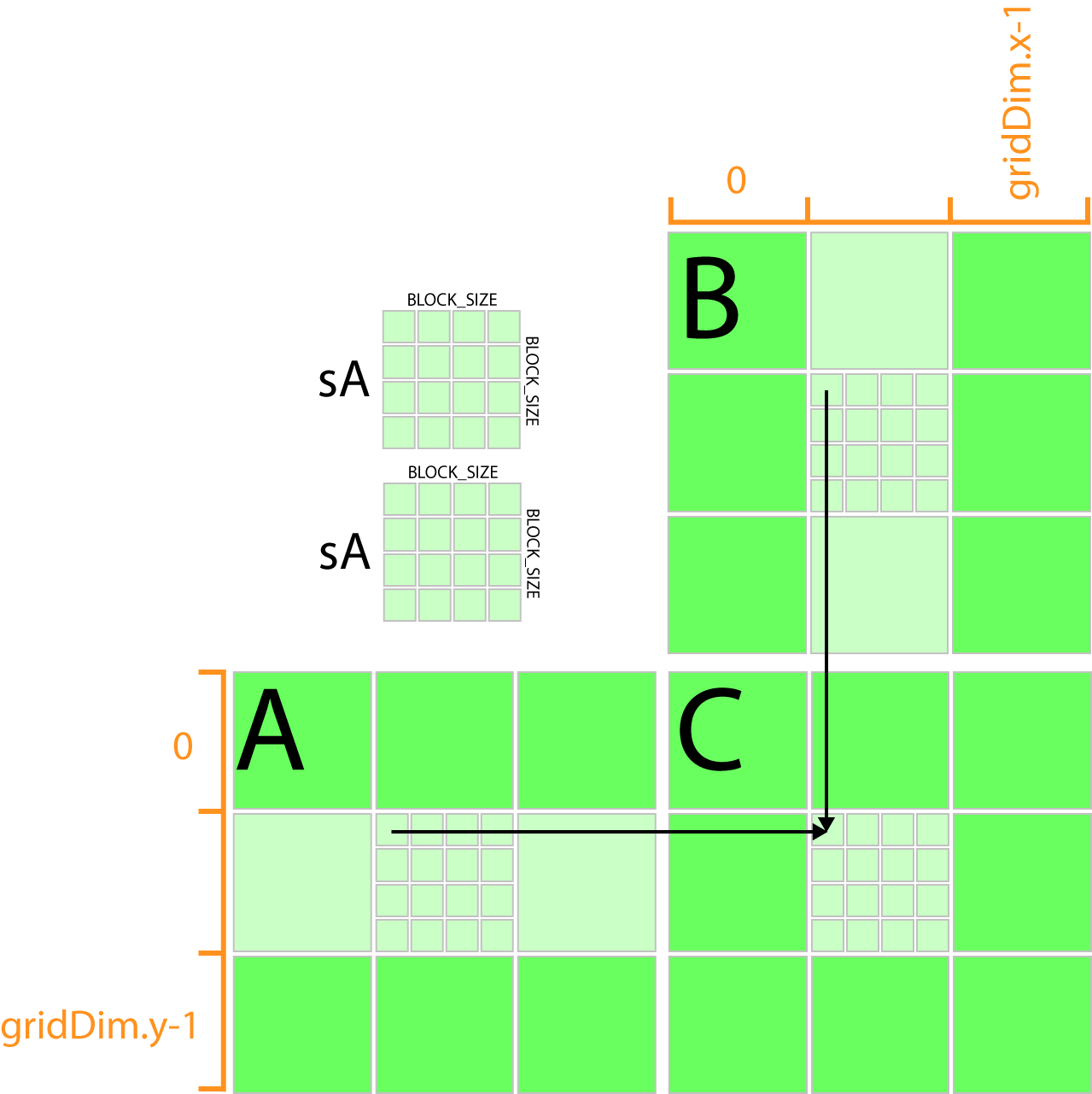
Cuda matrix multiplication shared memory example. Matrix multiplication tutorial This tutorial demonstrates how to use Kernel Tuner to test and tune kernels using matrix multiplication as an example. The manner in which matrices are stored affect the performance by a great deal. CCAB Keep As and s blocks in registers Keep s block in a shared storage No other sharing is needed if s height BS.
D_Awidth d_Astride Awidth. Shared Memory version 217 secs. It is assumed that the student is familiar with C programming but no other background is assumed.
MrowcolMelements row Mstride col typedef struct int width. This was the struct used. For example multiplying 1024x1024 by 1024x1024 matrix takes 4 times less duration than 1024x1024 by 1024x1023 matrix so I have transformed the matrices to square matrices by equalizing their dimension and filling.
Ive read the CUDA C Programming guide cuda 40 and I found a part 323 which described Shared Memory through Matrix Multiplication. I yi alphaxi yi Invoke serial SAXPY kernel. Specifically I will optimize a matrix transpose to show how to use shared memory to reorder strided global memory accesses into coalesced accesses.
Todays lecture Matrix Multiplication with Global Memory Using Shared Memory part I 2012 Scott B. Write the block sub-matrix to global memory. When I executed both versions the shared memory version is slower than the global memory version.
Im totally new with CUDA. Dimension of problem. Nx blockDimx 1.
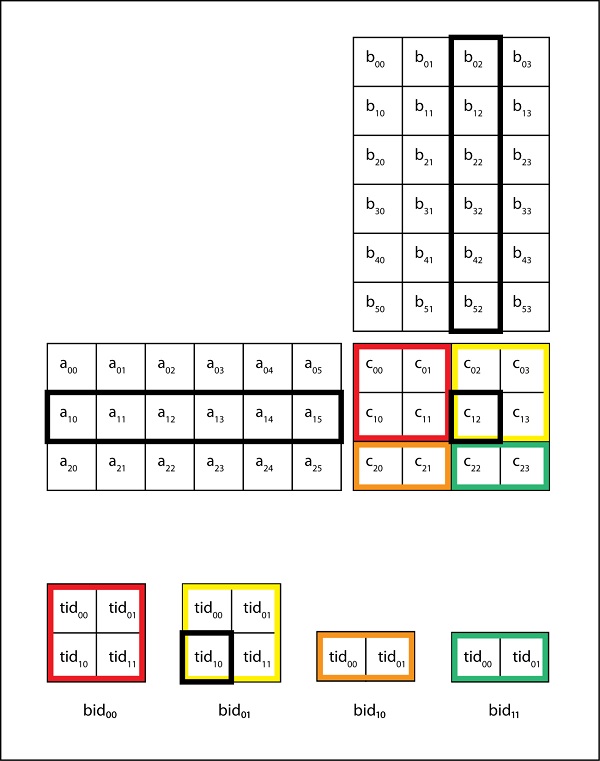
CudaError_t err cudaMalloc. If I use matrixes bigest the outcomes are the same the time wasting on shared memory version is 44 highest than global memory. Example of Matrix Multiplication Csub Astyk Bsktx.
But before we delve into that we need to understand how matrices are stored in the memory. However I dont get how to use the stride efficiently. This means we could only use 8.
CUDA Matrix Multiplication Shared Memory CUDA Matrix Multiplication Code and Tutorial cuda matrix multiplication codecuda matrix multiplication tutorial. Size_t size Awidth Aheight sizeoffloat. My last CUDA C post covered the mechanics of using shared memory including static and dynamic allocation.
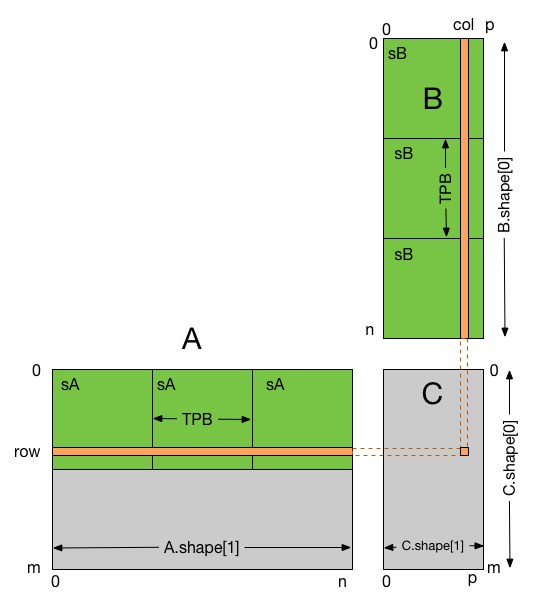
We use the example of Matrix Multiplication to introduce the basics of GPU computing in the CUDA environment. Synchronize to make sure that the preceding computation is done before loading two new sub-matrices of A and B in the next iteration __syncthreads. Each thread writes one element.
Void MatMulconst Matrix A const Matrix B Matrix C Load A and B to device memory Matrix d_A. Let us go ahead and use our knowledge to do matrix-multiplication using CUDA. In this post I will show some of the performance gains achievable using shared memory.
In the matrix multiplication example if we used 16 x 16 tiles then each block needs 16 x 16 x 4bytes per float 1K storage for A and another 1K for B. PrintfCopy A to device. 2147483647 65535 65535 Example.
Loading square sub-matrices A and B as coalesced into shared memory. Nx blockDimx. If there are multiple independent shared memory operations they should be grouped behind a common barrier command.
Why is it happening. 2D matrices can be stored in the computer memory using two layouts row-major and column. Nx ny 1000 1000 dim3 blockDim16 16 Dont need to write z 1 int gx nx blockDimx0.
Matrix Multiplication on GPU using Shared Memory considering Coalescing and Bank Conflicts - kberkayCuda-Matrix-Multiplication. Doing C A x B in random-access from shared memory. One platform for doing so is NVIDIAs Compute Uni ed Device Architecture or CUDA.
Example for coalescing layer. Global Memory version 144 secs. BS64 is the best result from experiments Choose large enough width of s block 16 is enough as 2164116 26way reuse.
Reading global memory line by line instead of element by element. Matrix multiplication is one of the most well-known and widely-used linear algebra operations and is frequently used to demonstrate the high-performance computing capabilities of GPUs. Baden CSE 260 Winter 2012 4.
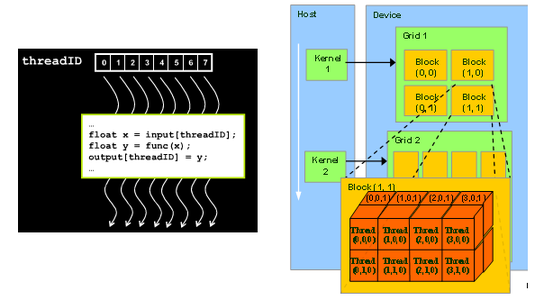
GPUProgramming with CUDA JSC 24.

2 Matrix Matrix Multiplication Using Cuda Download Scientific Diagram
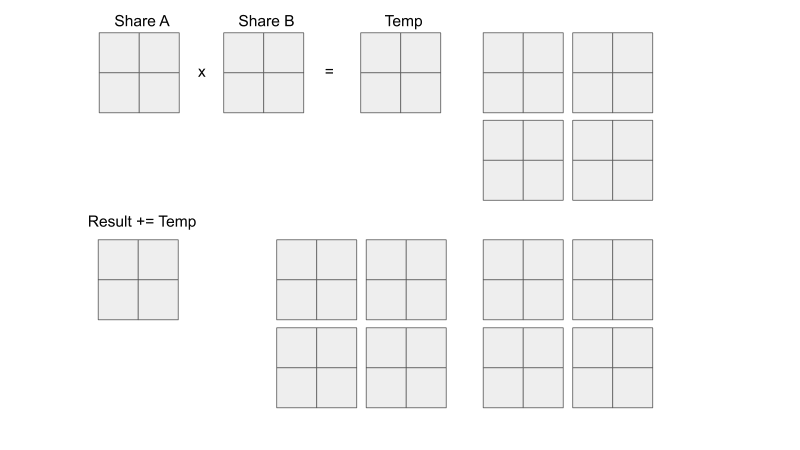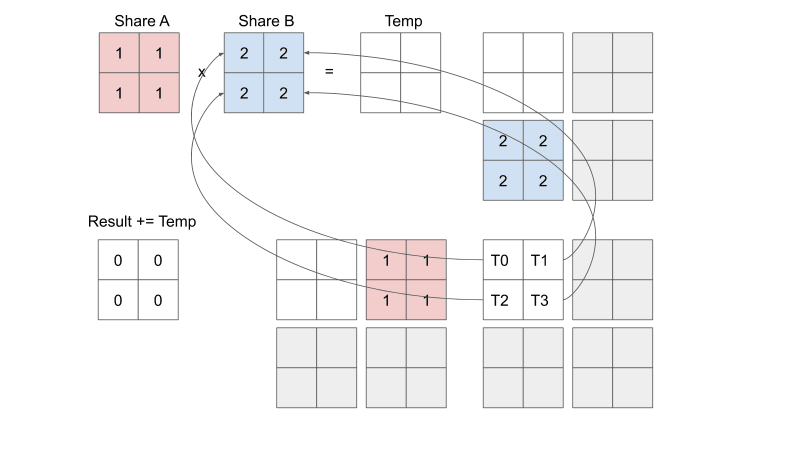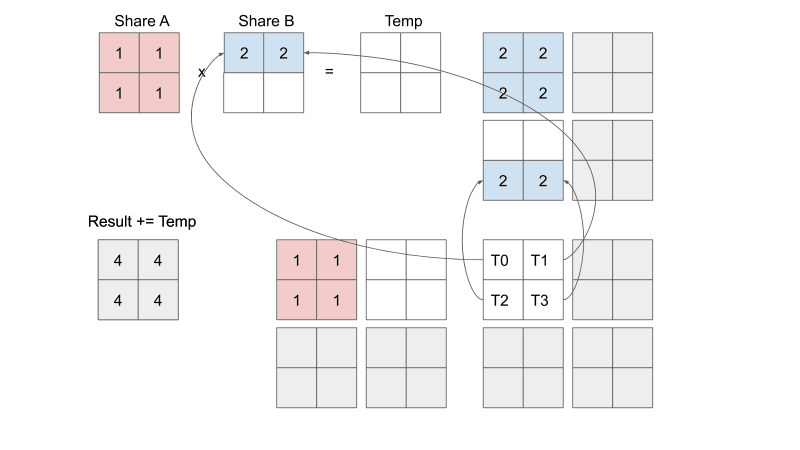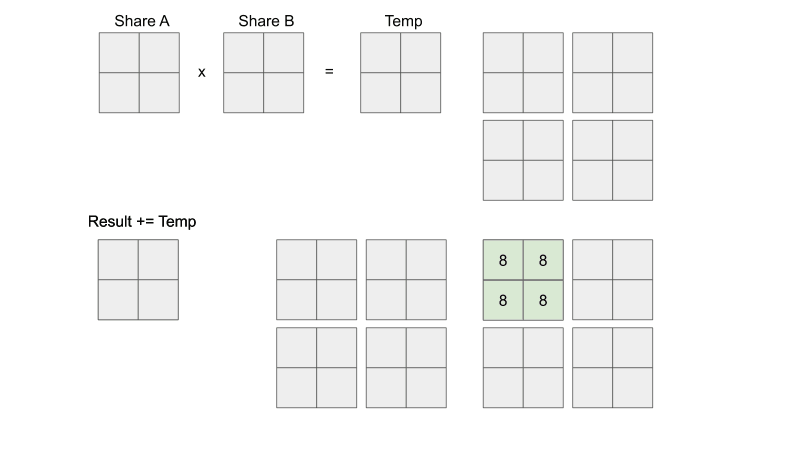
Tiled Matrix Multiplication
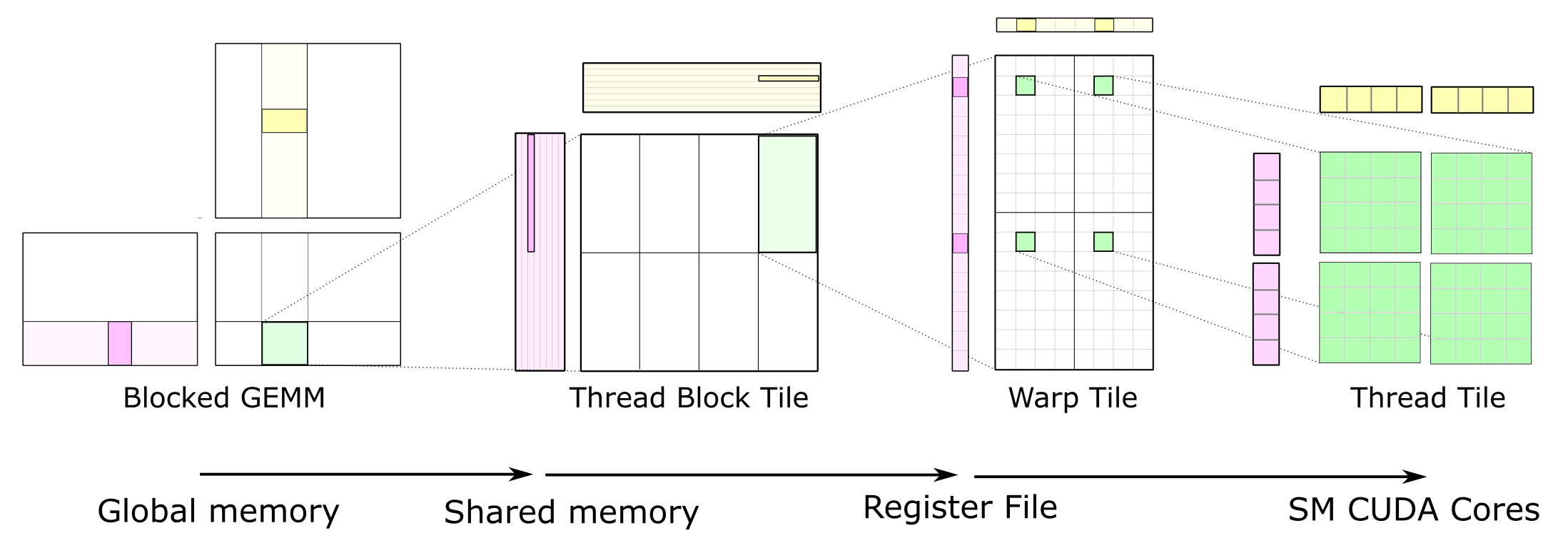
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Multiplication Kernel An Overview Sciencedirect Topics
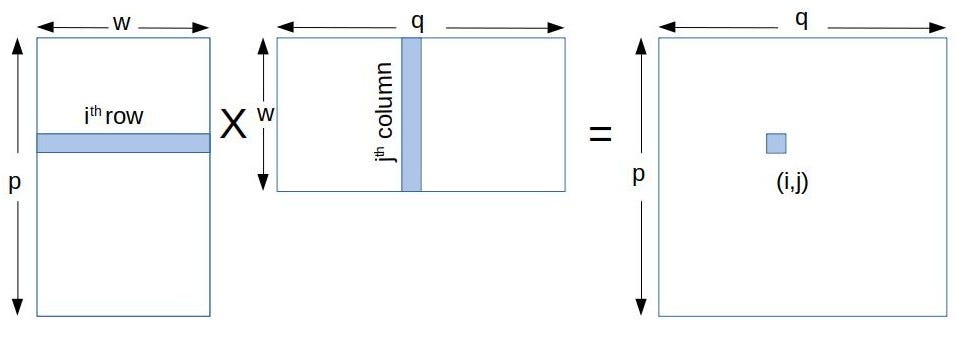
Matrix Multiplication In Cuda A Simple Guide By Charitha Saumya Analytics Vidhya Medium
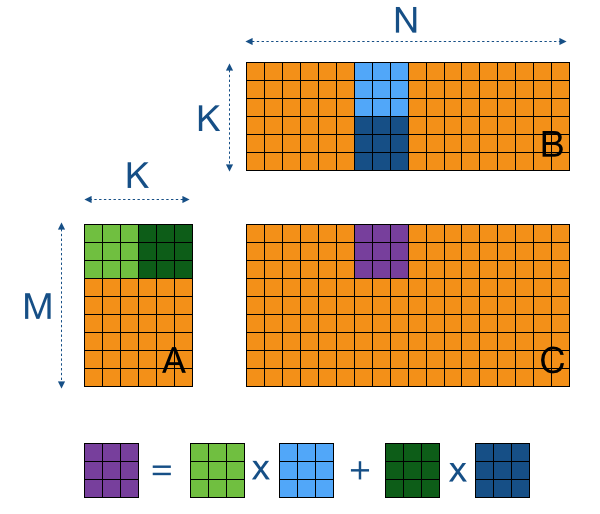
Opencl Matrix Multiplication Sgemm Tutorial
Introduction To Numba Cuda Programming
Cuda Reducing Global Memory Traffic Tutorialspoint

Matrix Multiplication Cuda Eca Gpu 2018 2019

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
Introduction To Cuda Lab 03 Gpucomputing Sheffield


Simple Matrix Multiplication In Cuda Youtube
Cuda Memory Model 3d Game Engine Programming
Using The Cuda Programming Model Leveraging Gpus For

Cs Tech Era Tiled Matrix Multiplication Using Shared Memory In Cuda

Cuda Python Matrix Multiplication Programmer Sought

Tiled Matrix Multiplication Kernel It Shared Memory To Reduce Download Scientific Diagram
Running A Parallel Matrix Multiplication Program Using Cuda On Futuregrid