Matrix Multiplication Cuda Program
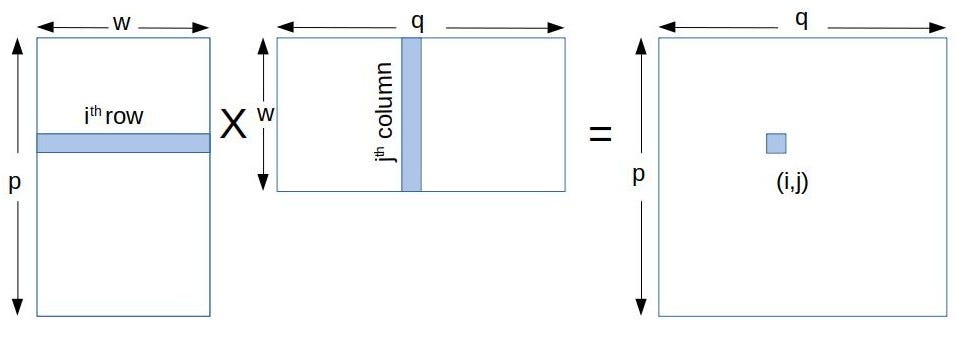
For matrix multiplication of m1 and m2 eg m1 x m2 we need to make sure W1 H2 and the size of the result will be H1 x W2. Broadcasted live on Twitch -- Watch live at httpswwwtwitchtvengrtoday.
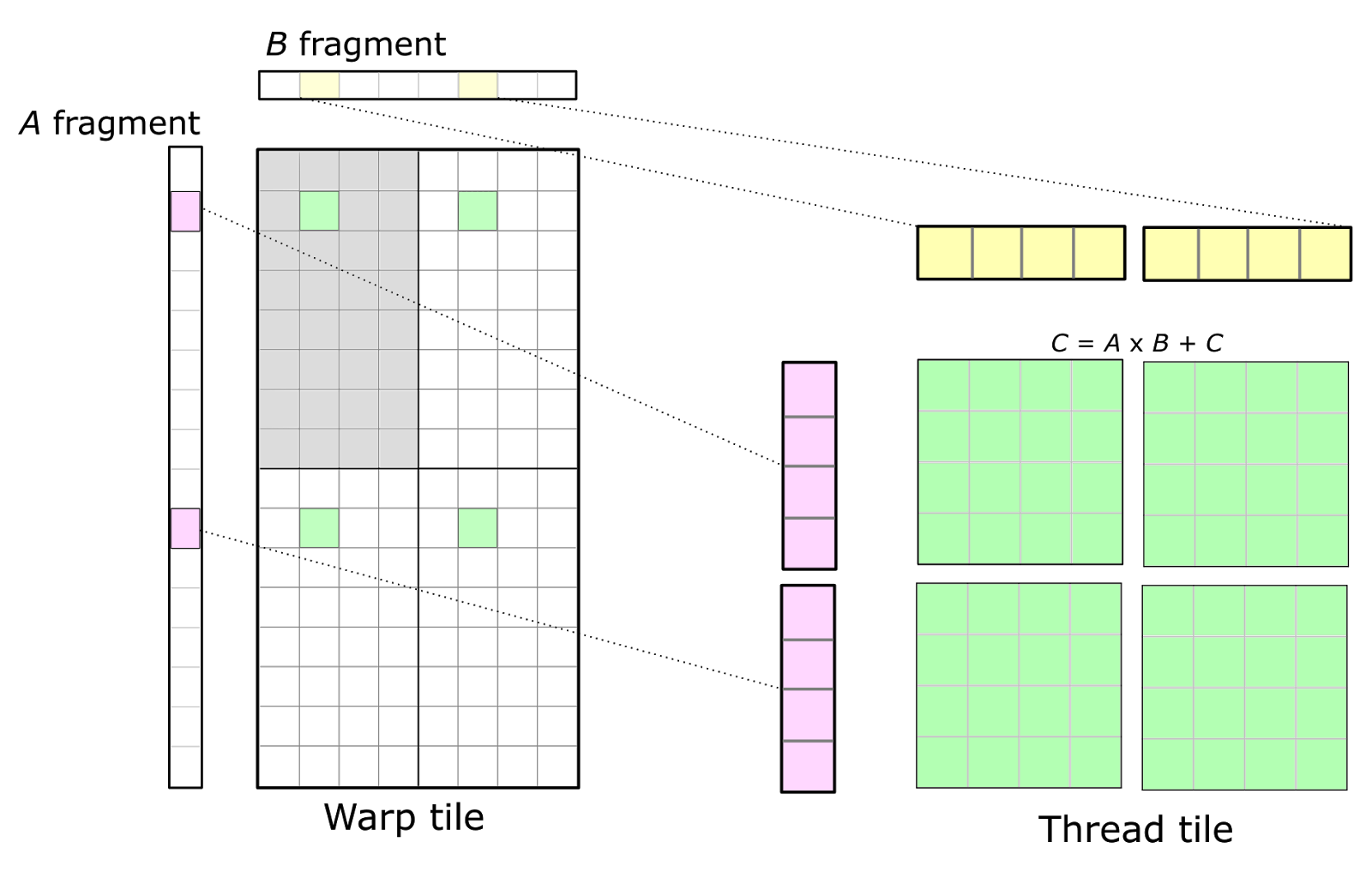
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog
Unsigned int row TILE_WIDTHblockIdxy threadIdxy.

Matrix multiplication cuda program. Each element in C matrix. The formula used to calculate elements of d_P is. Matrix multiplication kernels.
We will begin with a description of programming in CUDA then implement matrix mul-tiplication and then implement it in such a way that we take advantage of the faster sharedmemory on the GPU. Like m2 x m1 we. 21 The CUDA Programming Model.
Cs355ghost01 1939 mult-matrix 1000 K 256 NN 1000000K 256 3906250000 --- use 3907 blocks Elasped time 43152 micro secs errors 0. PrintfCopy A to device. Implementing in CUDA We now turn to the subject of implementing matrix multiplication on a CUDA-enabled graphicscard.
Matrix addition Implement matrix addition in CUDA C AB where the matrices are NxN and N is large. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK. It ensures that extra threads do not do any work.
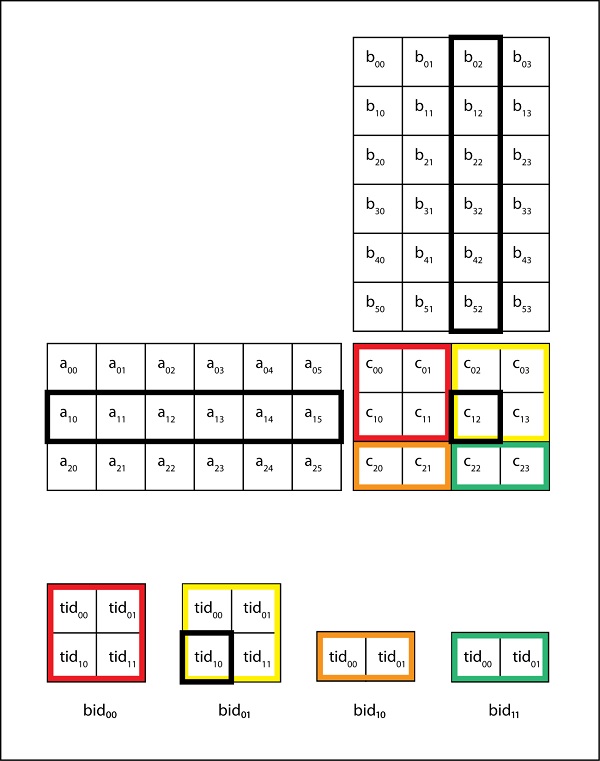
Each thread block is responsible for computing one square sub-matrix C sub of C. Pd row WIDTH col Md row WIDTH k Nd k WIDTH col. Please type in m n and k.
TILED Matrix Multiplication in CUDA by utilizing the lower latency higher bandwidth shared memory within GPU thread blocks. This is an extension of the program in the CUDA by Example book which adds two long vectors of length N. Inline void gpuAssertcudaError_t code const char file int line bool aborttrue if code cudaSuccess.
Size_t size Awidth Aheight sizeoffloat. Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. Shared.
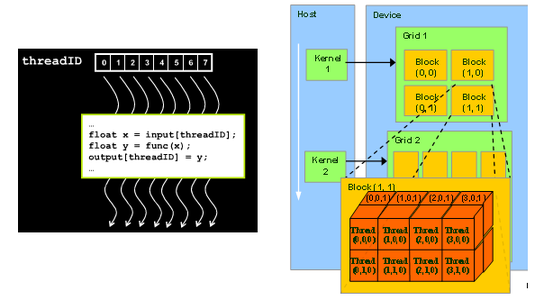
Computing y ax y in parallel using CUDA. __shared__ float Mds TILE_WIDTH. In this video we look at writing a simple matrix multiplication kernel from scratch in CUDAFor code samples.
Also refer to the url removed login to. Test results following tests were carried out on a Tesla M2075 card lzhengchunclus10 liu aout. Err cudaMemcpyd_Aelements Aelements size cudaMemcpyHostToDevice.
Time elapsed on matrix multiplication of 1024x1024. Taking shared array to break the MAtrix in Tile widht and fatch them in that array per ele. Matrix multiplication using shared and non shared kernal.
CUDA Programming Guide Version 11 67 Chapter 6. CudaError_t err cudaMalloc. Result rowWIDTHcol array1 rowWIDTHcol array2 rowWIDTHcol.
I yi alphaxi yi Invoke serial SAXPY kernel saxpy_serialn 20 x y. Void MatMulconst Matrix A const Matrix B Matrix C Load A and B to device memory Matrix d_A. MatrixMulSh float Md float Nd float Pd const int WIDTH.
Unsigned int col TILE_WIDTHblockIdxx threadIdxx. D_Awidth d_Astride Awidth. Matrix multiplication in CUDA this is a toy program for learning CUDA some functions are reusable for other purposes.
2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop void saxpy_serialint n float alpha float x float y forint i 0. Random facts about NCSA systems GPUs and CUDA QP Lincoln cluster configurations Tesla S1070 architecture Memory alignment for GPU CUDA APIs Matrix-matrix multiplication example K1. Include include define TILE_WIDTH 2.
The above condition is written in the kernel. Example of Matrix Multiplication 61 Overview The task of computing the product C of two matrices A and B of dimensions wA hA and wB wA respectively is split among several threads in the following way. Run make to build the executable of this file.
Nvcc -o mult-matrixo -c mult-matrixcu Sample. Define gpuErrchkans gpuAssertans FILE LINE.
Cuda Reducing Global Memory Traffic Tutorialspoint

Cs Tech Era Tiled Matrix Multiplication Using Shared Memory In Cuda
Matrix Multiplication In Cuda A Simple Guide By Charitha Saumya Analytics Vidhya Medium
Running A Parallel Matrix Multiplication Program Using Cuda On Futuregrid

Multiplication Kernel An Overview Sciencedirect Topics
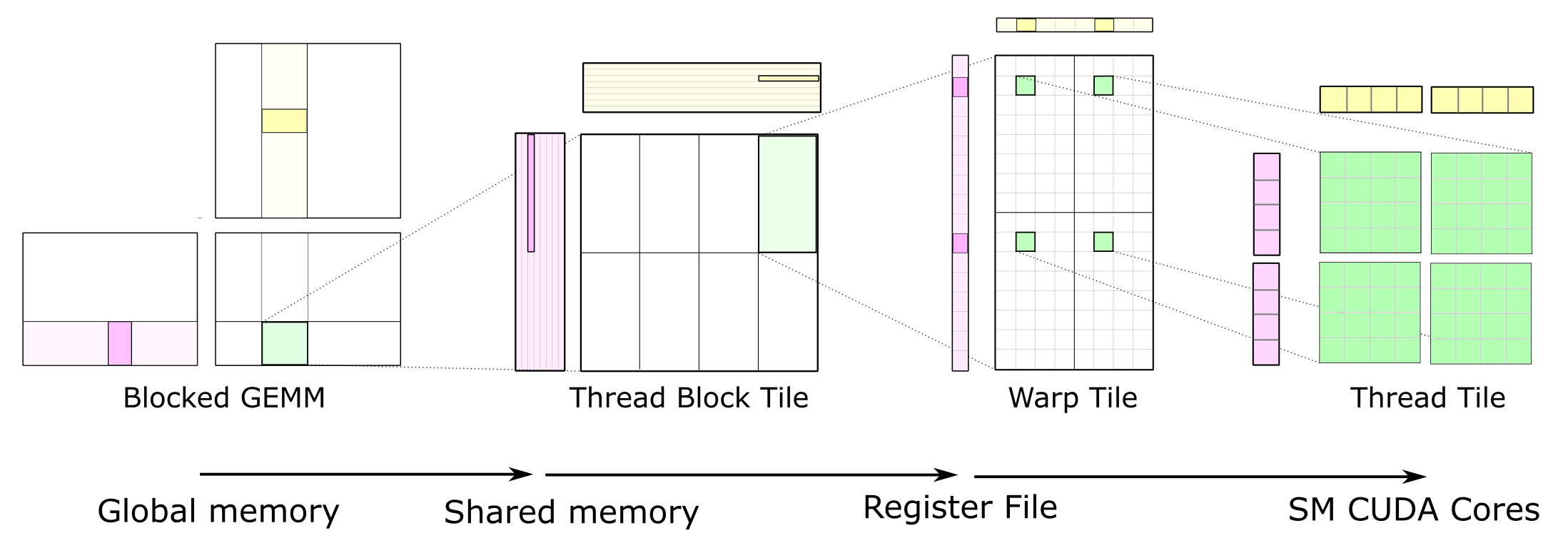
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

5kk73 Gpu Assignment Website 2014 2015

Picture Of The Code To Carry Out Matrix Multiplication Download Scientific Diagram

Tiled Matrix Multiplication Kernel It Shared Memory To Reduce Download Scientific Diagram
Https Edoras Sdsu Edu Mthomas Sp17 605 Lectures Cuda Mat Mat Mult Pdf

5kk73 Gpu Assignment Website 2014 2015

2 Matrix Matrix Multiplication Using Cuda Download Scientific Diagram

From Scratch Matrix Multiplication In Cuda Youtube
Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Simple Matrix Multiplication In Cuda Youtube
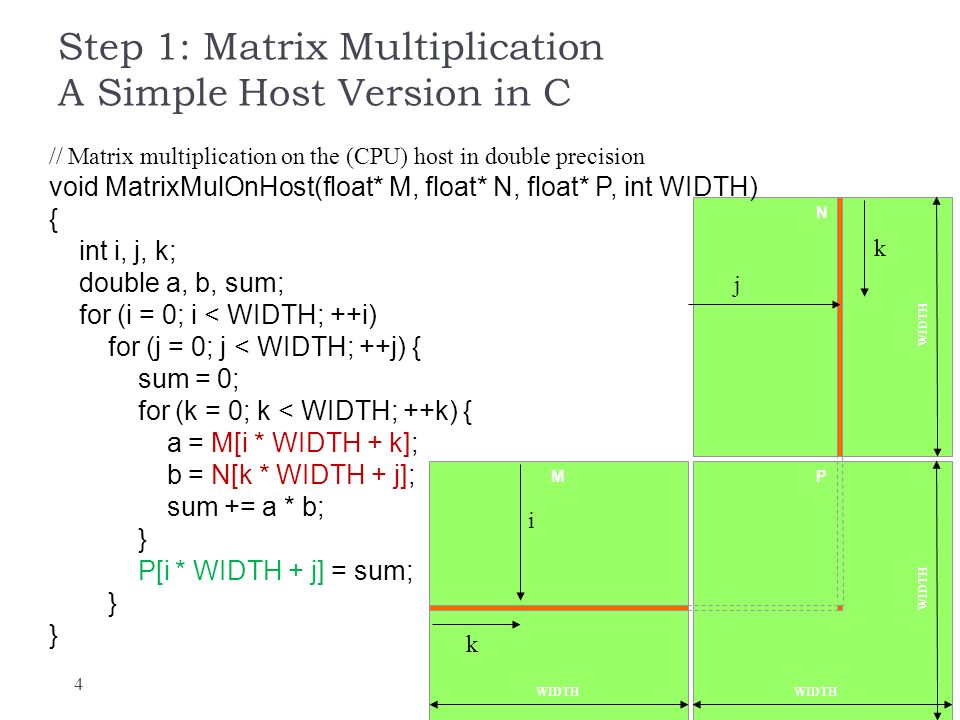
Matrix Multiplication In Cuda Ppt Download

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Programming With Cuda Matrix Multiplication Youtube

Matrices Multiplying Gives Wrong Results On Cuda Stack Overflow