Matrix Multiplication Bandwidth
What type of incorrect execution behavior can happen if one or. Matrix has nnz0number of non-zeros.
Matrix Operations On The Gpu Cis 665 Gpu
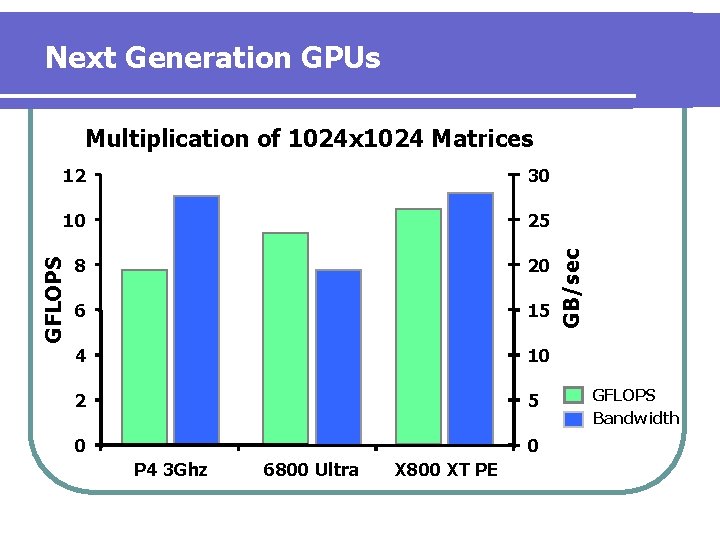
Thispaperexaminesmoree cientalgorithmsthatmakethe implementation of large matrix multiplication on upcoming GPU architectures more competitive using only 25 of the memory bandwidth and instructions of previous GPU algo-rithms.
Matrix multiplication bandwidth. Success of quantization in practice hence relies on an effi-cient computation engine design especially for matrix multiplication that is a basic computation engine in most DNNs. Matrix multiplication is one of the most well-known and widely-used linear algebra operations and is frequently used to demonstrate the high-performance computing capabilities of GPUs. Lennart Johnsson and Alan Edelman.
TILED Matrix Multiplication in CUDA by utilizing the lower latency higher bandwidth shared memory within GPU thread blocks. To figure out what the bandwidth is from your definition we need to figure out the smallest value of K that satisfies the condition. Draw the equivalent of Fig.
Verify that the reduction in global memory bandwidth is indeed proportional to the dimensions of the tiles. Matrix Multiplication on Hypercubes Using Full Bandwidth and Constant Storage The Harvard community has made this article openly available. Experiments were performed on a 3 GHz Pentium 4 CPU 512 KB L2 cache featuring peak performance of 12 GFLOPS and an L1 cache bandwidth of 447GBsec.
In this paper we propose a novel matrix multiplication method called BiQGEMM dedicated to quantized DNNs. 24x lower DRAM memory bandwidth and within almost one third of GPU SVMV performance on average even at 9x lower memory bandwidth. 1 Introduction The multiplication of matrices is one of the most central.
We tested our GPU algorithms on the ATI Radeon 9800XT a prerelease Radeon X800XT 500mhz core clock500mhz. For debugging run make dbg1 to build a debuggable version of the executable binary. Matrix Multiplication Chapter I Matrix Multiplication By Gokturk Poyrazoglu The State University of New York at Buffalo.
Additionally it consumes only 25W for power efficiencies 26x and 23x higher than CPU and GPU respectively based on maximum device power. Matrix multiplication tutorial This tutorial demonstrates how to use Kernel Tuner to test and tune kernels using matrix multiplication as an example. While calculating the arithmetic intensity of matrix multiplication above we assumed that the entire matrix data was available in the highest bandwidth memory.
Efficient Matrix Multiplication. This is not the case for large matrices commonly encountered in deep learning calculations. On the GPU su ered from problems of memory bandwidth.
Then by l for rebalancing the PE we must increase C-Cio by a factor of LY. Matrix-vector multiplication is very memory bandwidth intensive so scalability is typically limited by hardware contention regardless of how well the code is written. That is for this matrix multiplication computation we have M new cr2Mold.
Take the matrix. And 4 the number of non-zero elements for each rowcolumn are the same and equal to nnz N for input matrices and nnz0 N for output matrix. From 2 we see that this can be done only ifM is increased by a factor of cr2.
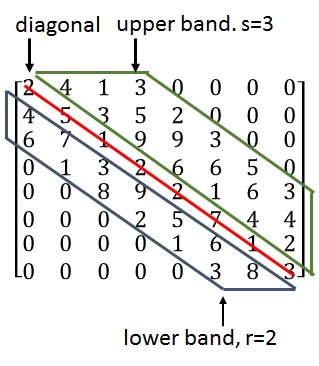
Please share how this access benefits you. Matrix A has upper bandwidth q if a ij 0 when j i q. The computation bandwidth is increased by a factor of r relative to the IO bandwidth.
For example on an Intel Skylake processor with 50GBs memory bandwidth the peak performance for multiplying ER matrices can be at most 50116 313 GFLOPS as shown in Fig. Inner Product This is arguably the most widely-known approach for com-puting matrix multiplication where a. 414 for an 88 matrix multiplication with 22 tiling and 44 tiling.
Matrix-matrix multiplication routine sgemm provided by ATLAS. Your story matters Citation Ho Ching-Tien S. The location of data in main memory can be important.
Keywords-sparse matrix vector multiplication FPGA. Run make to build the executable of this file. Matrix Multiplication on Hypercubes Using Full Bandwidth and Constant Storage.
However state-of-the-art column SpGEMM algorithms achieve less than 20 of this peak performance as discussed in a recent paper 24. Weights without memory bandwidth waste. A 3 1 4 0 0 0 1 5 9 2 0 0 6 5 3 5 8 0 0 9 7 9 3 2 0 0 3 8 4 6 0 0 0 2 6 4 as an example.
Intel Uhd Graphics 620 Gaming Review And Benchmark Scores Https Technewswith Me Intel Uhd Graphics 620 Intel Graphic Card Video Editing Application

Deep Learning Accelerators Based On Chip Architectures Coupled With High Bandwidth Memory Are Emer Machine Learning Applications Deep Learning Physics Problems

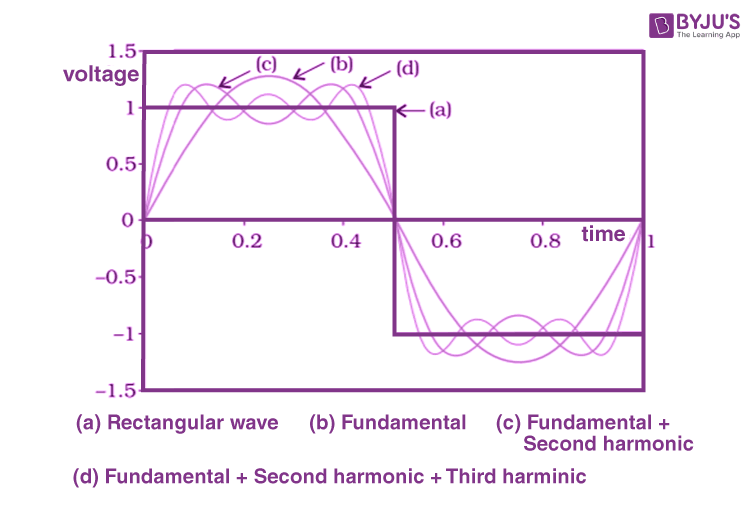
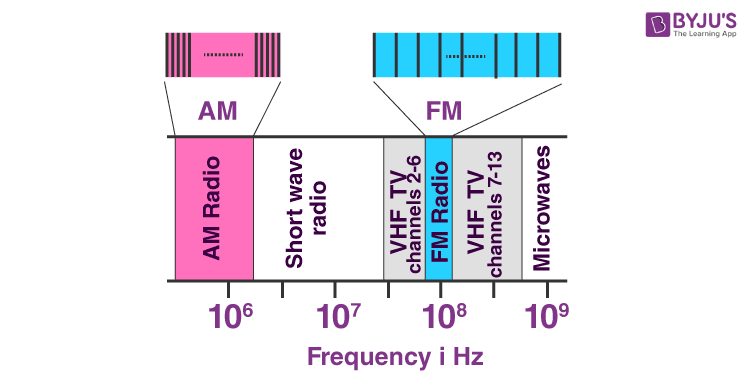
Bandwidth Of A Signal And Measurement Of Bandwidth Physics Byju S
Https Arxiv Org Pdf 2002 11302
Pdf Bandwidth Reduction In Sparse Matrices

Https Arxiv Org Pdf 2002 11302
Throughput Memory Bandwidth Vs Bandwidth Each Curve On The Graph Has Download Scientific Diagram

Acm Digital Library Communications Of The Acm

Https Arxiv Org Pdf 2002 11302
Https Arxiv Org Pdf 2002 11302
Memory Bandwidth An Overview Sciencedirect Topics

Https Arxiv Org Pdf 2002 11302
Architecture Of The Sql Framework Data Warehouse Information Technology Computer Science

Hierarchical Matrix Operations On Gpus Matrix Vector Multiplication And Compression

Getting Started With Dask And Sql Sql Data Science Java Library

Pdf Bandwidth Reduction In Sparse Matrices

Learn More About Tensorflow Google S Software Library Designed To Simplify The Creation Of Machine Learning Machine Learning Machine Learning Models Learning

Prgramming Assignment
Bandwidth Of A Signal And Measurement Of Bandwidth Physics Byju S
